
DevOpsDays 2025 活動紀錄
前言
自從前幾年開始玩自組 NAS 後,伺服器架構、網路設定以及容器化管理就一直是我的支線任務,當越來越常聽到 DevOps 這個名詞後,一查發現似乎就和我在玩的事情很像,便開始起了興趣。
這次很幸運能拿到公司提供的贊助票參加 DevOpsDays。除了希望能更深入了解這個領域使用的技術和工具外,也期待透過這次的活動,能對接下來新產品的 Infra 建置能有所幫助。
當然,因為使用公司資源參與,帶點「土產」回去分享是免不了的。在整理活動的筆記之餘,也決定來整理一篇活動紀錄到部落格與大家分享。
這邊之所以說是「活動紀錄」而不是「心得」,是因為心得對我來說更像是回饋跟反思,但其實我更想寫的是一個參加的「過程」,所以會比較流水帳一點。
DevOps 是什麼
大部分人聽到 DevOps,第一個想到的就是 CI/CD,至少我一開始也是這樣想,但其實 CI/CD 只是 DevOps 實踐的一部分。
DevOps 並不是單純的「工作職責」,更像是一種「文化與實踐」。
原意為 Development(開發)與 Operations(運維)組合而成,強調開發團隊與運維團隊共同合作、共同負責產品品質,建立持續改善的流程。
舉個例子,以往開發團隊完成產品後,交給維運團隊負責部署及維護,但過程中可能會發生以下狀況:
- 程式在測試環境運行正常,但到了 production 因為環境變數或配置設定差異導致錯誤。
- 部署手動操作,出錯機率高且容易造成服務中斷。
- 缺乏有效的即時監控,程式效能問題無法及時發現。
- 開發與維運環境版本不一致,導致問題難以重現,互相推卸責任。
這些問題常造成團隊內摩擦,而 DevOps 正是希望透過文化、流程與工具來改善這些痛點,例如:
- 使用 CI/CD 自動化部署流程,避免人為失誤。
- 透過 Kubernetes 實現服務的自動橫向擴展,快速回應負載變化。
- 使用 Prometheus 搭配 Grafana 進行系統監控,提升問題發現的即時性與視覺化。
Dev 和 Ops 從開發初期就緊密合作,共同擁抱錯誤,透過持續迭代來逐步改善產品穩定性和開發效率。
DevOpsDays 活動摘要
和大多 Conference 一樣,DevOpsDays 在同一個時段中會有多場演講,參加者可以自由根據興趣選擇想聽的內容。
除此之外,DevOpsDays 有 Workshop 議程讓大家動手,也有提供給新手聽的 Bootcamp 議程,算是相當不錯。
議程時間表有個要注意的地方是「工作坊的結束時間和其他議程是不同的」,這部分沒有在表格上特別被視覺呈現出來,所以安排時需要留意一下。

DevOpsDays D1
這次活動在文創大樓六樓,一早就擠著板南線從國父紀念館站走過來。
因為有打算參加工作坊,在官網上有寫著當天 08:30 起統一開放登記,所以大概抓 8:15 左右抵達,現場出示證件報到後拿到參加證。
先到報到櫃檯領參加證,上面會有一個號碼用來報名工作坊時叫號用。

報到櫃檯後面排起人龍,都是要報名的 Workshop 的,幸好因為來的算早的關係,當天想聽的都有報名到,隔天的 Workshop 則是隔天早上才能登記,所以明天得再早起一天。
第一個議程 9:30 才開始,報名完工作坊後發現還有時間,想說去吃個早餐。
但當時外面下雨,而且要從松菸走一段路去看看附近有什麼店有開有點麻煩,好在旁邊馬上發現了 7-11 的販賣機,用悠遊卡買了飯糰跟拿鐵,可以自助弄杯拿鐵還蠻有趣的。

小插曲是我的悠遊卡餘額不足,剛好最近換了一張 SuperCard 的悠遊卡,馬上發揮功用…
場地基本上就是一條走廊上有很多間教室,根據想聽的議程進到對應的教室,每個教室外都有放置零食茶水桌,可以自由取用。

因為要報名的工作坊或 Bootcamp 會在 10~15 分鐘前開始依報名順序叫號,如果錯過的話會再重新叫號一輪,最後開放想聽的候補進去。
而比較早報名就代表著會比較早被叫到,所以我差不多抓 20 分鐘左右開始往教室附近移動,早點報到的唯一好處就是能先選座位。

RAG打造企業AI知識庫:把一甲子功力傳給新人
簡報:https://chechia.net/posts/2025-06-06-devops-rag-internal-ai/
這個工作坊會需要啟 Docker 開發環境,其實官網上有工作坊的行前通知,但我是來了後才知道…
不過我看很多人好像也跟我一樣沒注意到,所以開始前也拖了一點時間讓大家安裝,講師還很貼心提供幾台遠端 VM 讓大家可以使用,但看到 Ngrok 我就心累了,果斷直接拉專案來裝 Docker 開專案。
好在會場網路比預想的快很多,環境一下就裝完了。

這場主要講解 RAG 基本知識、LangChain、向量資料庫,搭配 OpenAI 並提供 Token,讓我們用 Python 搭配 Jupyter Notebook 調整與測試結果。
整個 Workshop 內容很多,講的節奏也是相當快的,不熟悉操作或相關概念的話很容易追不上,至少我自己是跟的有點辛苦。
自助式大數據平臺:平台工程的策略與價值

這場對我的誘因是講者來自台積電,換到了意外非常大間的教室…
主要介紹台積電成立了平台工程的部門來協助其他單位做數位轉型,內容對我來說相當遙遠,再加上要先提早去工作坊,只聽了 15 分鐘左右就撤退了。
Deploying Autoscaling CI/CD Runners
簡報:https://s.itho.me/ccms_slides/2025/6/17/0452abce-c141-4fdb-b9df-5d4ce24af020.pdf
一樣需要先準備好 K8S 環境,幸好遇到第一場的問題後我就先處理好了。
我覺得最平易近人的工作坊,教你使用 GitHub Actions 與 K8S 建一套 CI/CD 方案。

至於為何需要搭配到 K8S,其中之一是 GitHub Actions 是用執行分鐘數計費,跑在組織的 Private Repo 很快就不夠了,再來我還有想到資安考量,大公司通常不希望跑在第三方機器上。
主要用到的工具有:
- Minikube:K8S 原生提供的小工具,快速瞭解 K8S 相關的東西,用 Docker 相關的技術讓你快速組出叢集
- Helm:管理 K8S 設定檔的工具
- K9S:K8S 的管理工具
- Actions Runner Controller(ARC):可以在 Kubernetes Clusters 中動態部署、管理並監控託管的 GitHub Actions Runner
一開始先從 CI/CD 工具的歷史開始講,再來一個個指令解釋跟帶實作,我認為節奏把控的很不錯,超讚。
中午時間
工作坊的時間會跟一般議程不一樣,像上一場是從 11:30~13:00,而下午議程又從 13:30 開始,所以包含 上廁所 > 拿便當 > 找地方吃 > 收拾,我的吃飯時間不到半小時。
雖然吃得有點趕,但是便當蠻好吃的。

用恐龍書剖析 AWS Legacy Infra 的效能瓶頸
簡報:https://s.itho.me/ccms_slides/2025/6/18/29f3d467-3937-4a56-b7b5-08443f0a91ba.pdf
講者分享用大學學過的系統知識書來分析 AWS Infra 遇到的問題。
開頭貼心的預告了這場不會造成 AI 焦慮(笑

簡單來說筆者發現 AWS 上的 Node Server 不通,開始分類狀態、排查與測試。
透過從恐龍書中學習的知識,考慮了效能、連線數上限等等後,最後從 ALB 轉換成 NLB 後暫時解決。
呼籲基礎知識的重要性,即使有 AI,沒有基礎知識也問不出想要的結果。
附上我最喜歡的梗圖之一:

Observability 入門班:可觀測性的核心技術架構與 OpenTelemetry 實作指南
簡報:https://speakerdeck.com/unclejoe/devopsdays-taipei-2025-observability-opentelemetry
我個人最期待的一堂,特別是發現這次好多人都在講 Observability。
Observability(可觀測性)單字從「O」到「Y」之間有 11 個字母,所以又簡稱 O11y,命名跟 I18n、K8s 概念一樣
指的是透過外部系統的輸出,能夠多有效來推斷內部狀態的一種能力。
由於現在的服務架構相較於以往複雜許多,難以用傳統的監控來快速定位問題根源。例如: CPU 佔用很高,只能反應一個現象,但不知道造成的原因。
這時候就得提到 Observability 的三大支柱:
指標(Metrics):
如系統效能、磁碟空間、回應時間等,輕量、高頻寬,每秒 or 每分搜集一次,量化且直覺,適合追蹤系統變化。
但難以深入了解問題背後的原因,也缺乏上下文細節,可能會因為取固定間隔的搜集方式影響搜集關鍵的細節。
日誌(Logs):
如 HTTP Access Log、Error Message、Warning Log 等,透過 JSON 或 KeyValue 變成結構化,細節較為豐富,也可以儲存歷史。
容易產生、標準化日誌框架,但資料量大,成本上升,彙整分析也很不容易
追蹤(Tracing):
呼叫之間的關聯,可觀測呼叫的時間及順序,提供 traceId,透過時序化串接多個 Spans。
一個 Spans 代表一個完整的操作或是工作階段的時間區段,整段操作會有唯一的 Span ID。
適合釐清內部服務的問題,有效盤段效能瓶頸跟異常點,但難以揭露長期的趨勢,多樣化的追蹤路徑會難以比對跟歸納,無法解釋效能不佳的問題,需要搭配 Logs。
指標告訴你有問題發生,追蹤告訴你問題發生在哪,日誌幫助你找出為何發生。
以上三者互相需要,另外還有提到 Observability 資料處理流程 和工具選型,不得不說工具的數量真的很可觀…

OpenTelemetry(Otel)
這次只要提到 O11y 的分享,都一定會提到 OpenTelemetry。
OpenTelemetry 簡單來說就是可觀測性的開源框架,目的在於統一『收集、處理、傳送』的標準,並提供支援多個語言的工具來自動或手動收集、處理和傳送分散式系統中的指標、日誌與追蹤資料,協助建構現代化的可觀測性架構。
至於整合後是什麼概念,對我來說沒實作過 Observability 的人來說可說是有看沒有懂,就只能等未來有機會再研究了。
最後還整合了導入推薦的工具、SaaS 服務等等,我覺得真的超貼心,對相關領域的人入門可能是很有幫助的一場。

從開發到架構設計的可觀測性實踐
簡報:https://speakerdeck.com/philipz/cong-kai-fa-dao-jia-gou-she-ji-de-ke-guan-ce-xing-shi-jian
和上一場內容差不多就不贅述,節奏再更輕鬆一點,提到比較多 OpenTelemetry,簡報圖示化較多相當易懂,建議可以直接看簡報。
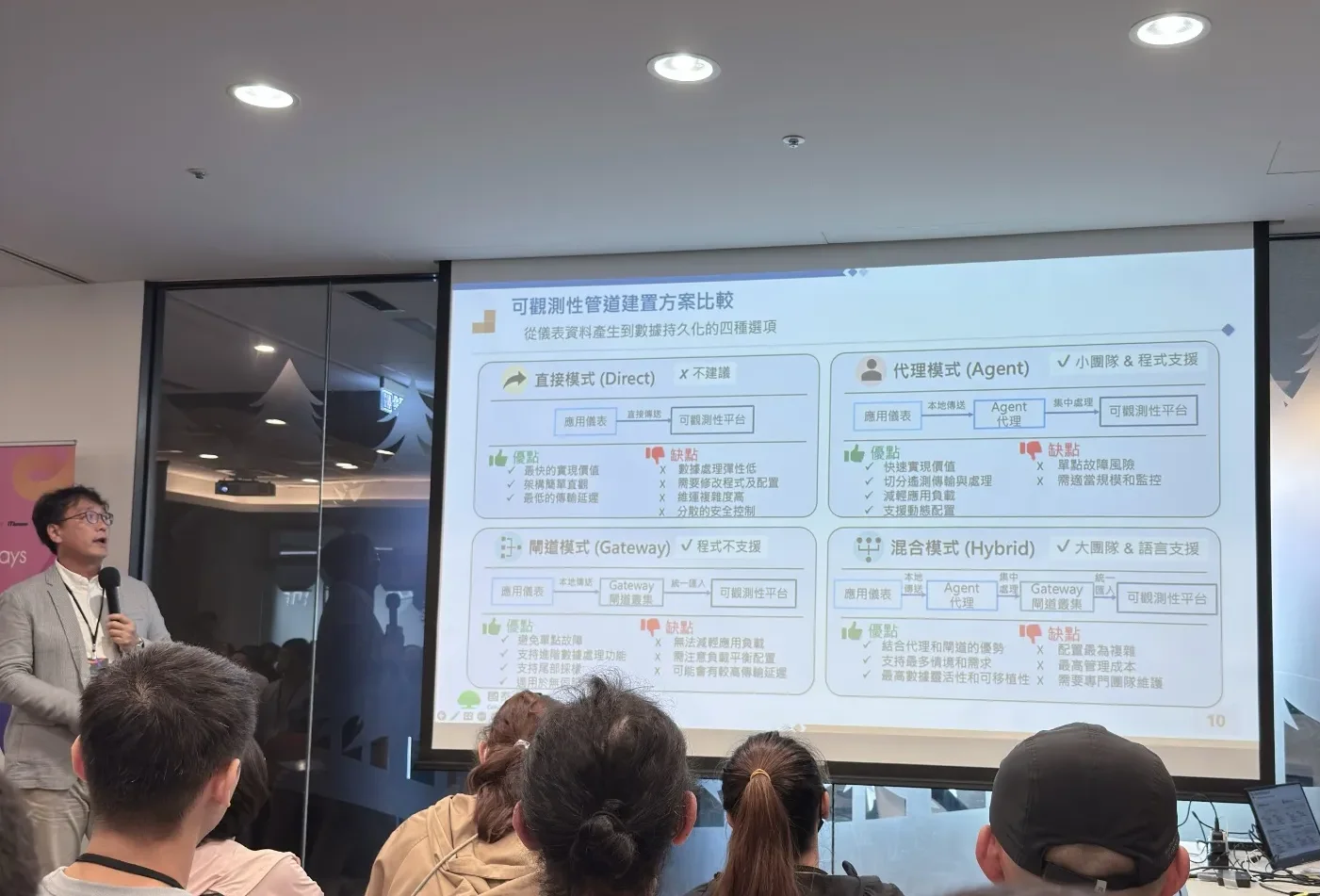
為什麼你裝了一堆 O11y 工具,卻沒人用?
簡報:https://s.itho.me/ccms_slides/2025/6/12/309d884f-48f6-4eaa-8021-582969a490ad.pdf
工程師大實話,很有趣的一場,很多好笑的真實例子直接打中我。
例如以工具為中心的技術導入,擺著看起來很厲害但其實只是在浪費電;設置一堆警報但事實上都不是重要的警訊。

真正導入 O11y 很常落入 Ops 的工作,但實際可能需要 Dev、Ops、管理層一起共享責任,而 Dev 也該學會如何追蹤 trace、定位問題、看 metrics、dashboard 等等。
一開始導入先挑選最賺錢、最可能出事的路徑做追蹤,並且避免紀錄過多低價值的 Metrics,除了能減少雜訊外也能避免丟失成本。另外設計 dashboard 也該考慮這個指標是能幫助誰。
記得工具只是手段,問題定義才是王道,找出業務痛點、找出影響、根據範圍決定要埋跟要搜集的 Metrics 在哪邊。
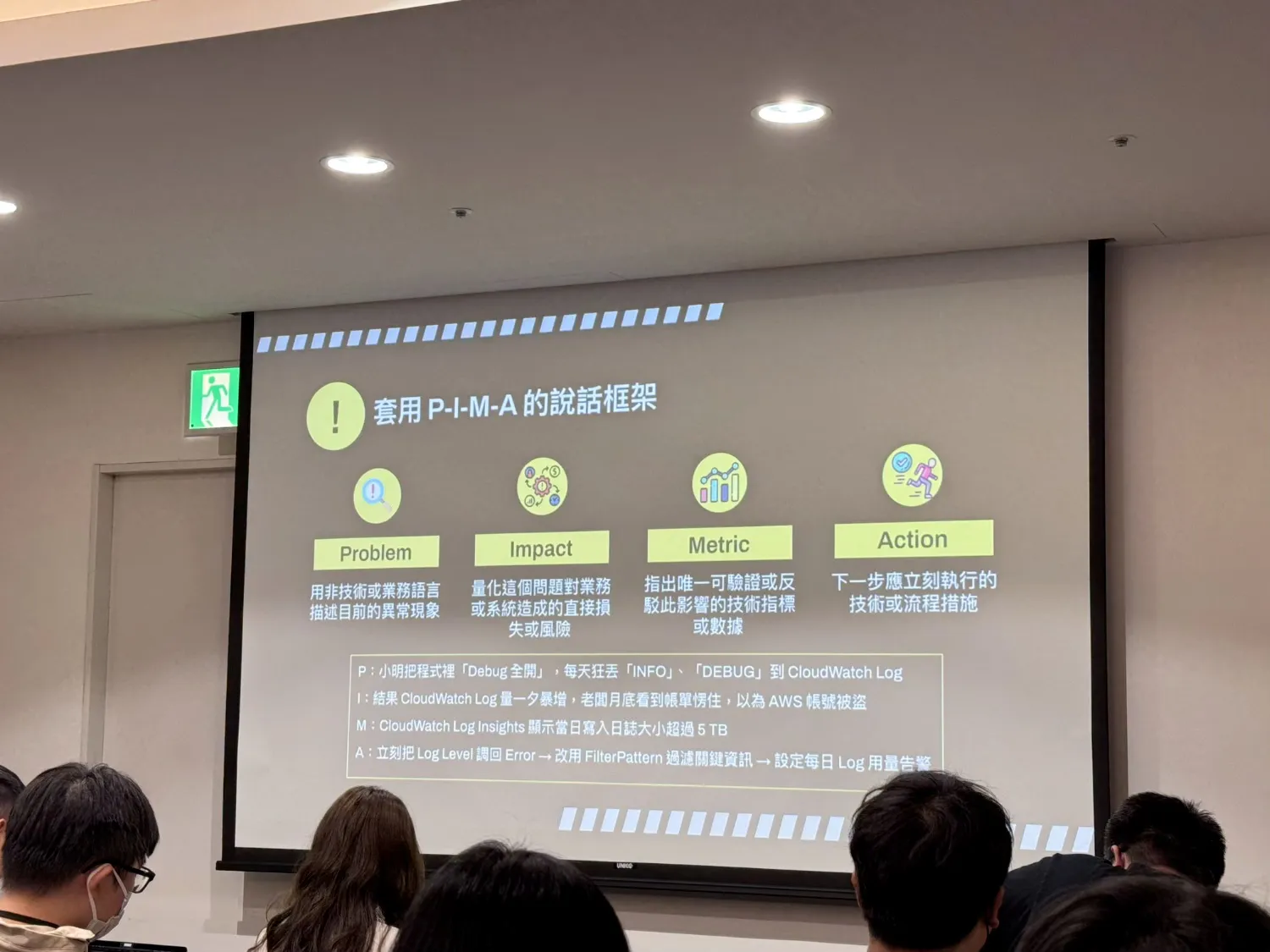
問題只要被明確量化,就容易知道怎麼追蹤指標,往後才容易被追蹤指標。
DevOpsDays D2

第二天的天氣比昨天更爛…
然後大家有了第一天的前車之鑑,第二天排 Workshop 的登記早早就大排長龍。

當然這完全在意料之中,所以我比第一天還更早來,也都有報名到。
如何利用 GenAI 工具輔助開立手動測試個案
簡報: https://s.itho.me/ccms_slides/2025/6/16/b67da3ce-87bf-4278-abab-3c1de78aa596.pdf
採用互動方式的 Workshop,先透過不同桌分組後,在白板討論並讓小組討論回答。
說真的沒想過來 Conf 還要分組互動的,不得不說有點抗拒。
先從 GenAI 的原理後開始根據例子思考可能的問題,接著提供和剖析各種 Prompt 的範本類型後,讓大家進行一個高鐵訂票系統的 test case 的練習,透過實際操作來看看哪種 Prompt 的 test case 比較好,或是還有哪些不足。

從中算是學到了比較有結構的 Prompt 差異,畢竟我在實際開發時並不會對 Prompt 想的那麼細,甚至還能到範本的程度。
另外 Get 到的一個啟發是:大家不懂測試,所以 AI 當然也懂得不多,因此人要知道如何設計你的測試,AI 才能給你有邏輯的測試案例,有領域知識還是很重要的。

【Bootcamp】從零到一:搭建你的第一個 Observability 平台
簡報:https://s.itho.me/ccms_slides/2025/6/16/62f78dd5-7e6d-4d4f-baad-7ef6ba3ae864.pdf
還記得要報名的工作坊或 Bootcamp 會在 10~15 分鐘前開始依報名順序叫號嗎?
由於上一場跟這場中間的時間沒有 buffer,然後我報名的順序又比較早,所以即使我提早離開教室先移動也依然過號了,這點我覺得真的蠻鳥。
不過等叫完一輪後就能在過號進去,所以問題不大。
這場一樣是要動手做,一開始會先介紹為什麼需要 Observability,簡報用上這圖我覺得太天才了…超好笑XD

實作則是使用 Docker Compose 建立 Observability 平台,開始學習釐清資料流與各元件功能,然後是可觀測性資訊 Logs、Metrics、Traces 的生成、收集、儲存、使用。
先簡單介紹了 Observability 後,開始教我們怎麼用 Prometheus、Loki、Tempo 搭配 Grafana 來查看 API 的一些資訊,然後還可以設定 Alerting 等等。

講者演說蠻有趣的一場,大概對於監控上的流程認識有個雛形,但怎麼操作應該很快就會忘記了XD
中午時間
因為今天對 11:30 的工作坊沒興趣,所以就先去吃飯了。
今天才注意到是老三餐盒,知道這家蠻有名的,還是第一次吃到。

說真的菜色很不錯,好吃!

然後吃的時候才發現沒議程的教室,投影片會放一些活動提示…
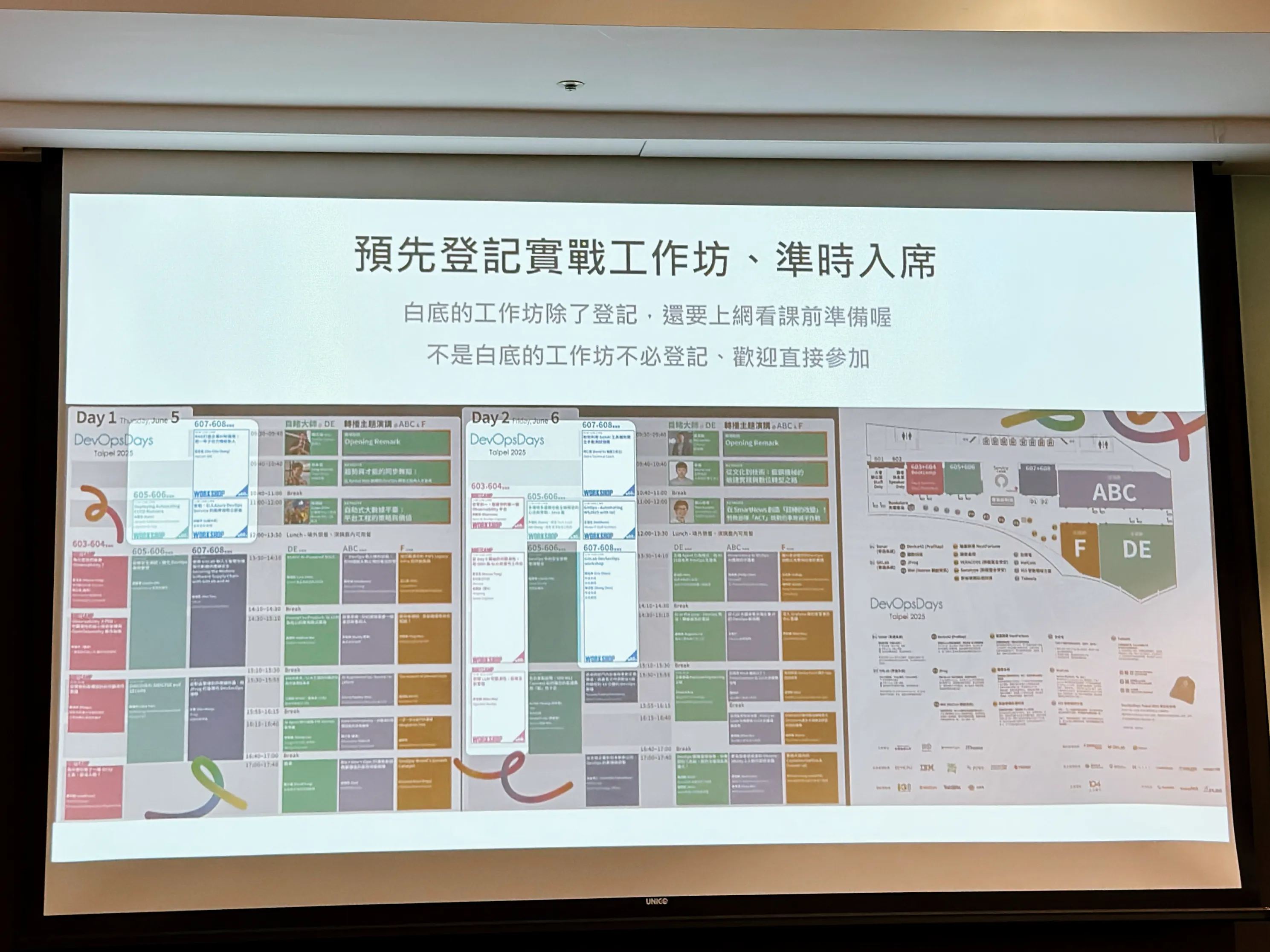
好吧我真的是第一天才知道要上網看課前準備,而且官網某一頁好像也有寫(就偏偏不是寫在議程表那頁…),希望下次發送行前通知也可以順便提醒一下大家。

Bootcamp 感覺真的不錯,感覺特別適合我這種萌新,而且我應該也是第一次參加到有工作坊或是有 Bootcamp 的 Conf。
吃完後還有足夠時間,就去逛一下贊助廠商的攤位看一下工作機會跟拿拿贈品,主要的目標是台積電XD

有些廠商還會自己做 App 搞抽獎活動,而且好像可以抽電視,我也好想要ww

【Bootcamp】從 Day 0 開始的可觀測性:用 ODD 與 SLO 的實作工作坊
簡報:https://s.itho.me/ccms_slides/2025/6/16/eb134233-005e-403c-ab6f-8b5a0343f6ac.pdf
感受到「我是誰,我在哪裡」的一場(笑)
一開始會讓大家依入場坐的桌子分組,然後講了一些關於 SLA、SLO 等等的前情提要後,就開始設計系統 SLO result 的練習。

過程會抽事件卡,然後評估可能的問題點跟如何調整和設計,然後透過 FigJam 整理。
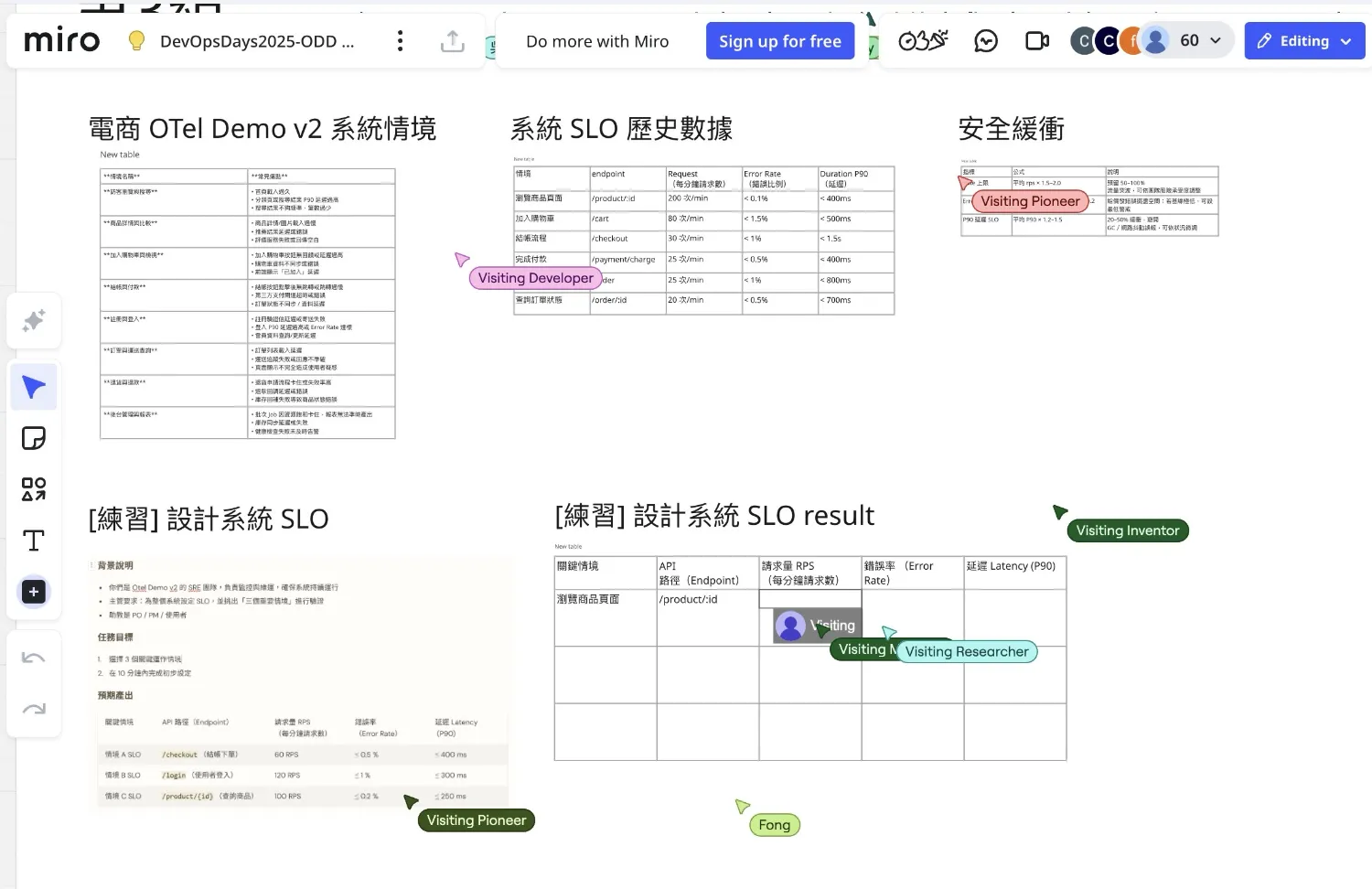
中午明明看 Bootcamp 是新手友善的議程,結果更像是實戰營…
只能說隔行如隔山,說真的大部分我都不太懂要幹嘛,最後只能幫忙評估和設計 API 的功能,剩下都靠同組的 SRE 在產出,然後莫名的小組表現還名列前茅。
別再用 Mock 騙自己了!Testcontainers 在 CI/CD 的實戰攻略
簡報:https://s.itho.me/ccms_slides/2025/6/16/ea22dc73-f6bc-427c-a802-b4bbe3b3bf1a.pdf

這場我一開始就超有興趣,因為前段時間我們團隊才在煩惱如何測試 DB 這段,畢竟跑 CI/CD 時,unit test 只能 Mock,就無法驗到操作 DB 這段的情境。

主要是在講玉山的團隊分享了他們的架構,然後如何透過 testcontainer 來解決他們的痛點。
可惜聽下來好像不太適合我們團隊目前的情境,小小可惜。
然後簡報部分的手繪風格真的好看,我好喜歡。

從混亂到有效治理:Policy as Code 在跨團隊 CI/CD 的實踐與應用
簡報:https://s.itho.me/ccms_slides/2025/6/16/90b57bf0-3996-4fdb-85f7-839f8e812352.pdf
一樣是玉山的團隊,主要提到當服務管理在地端時,通常要使用會透過表單之類的方式來配置,然後回到開發者手上,開發者沒辦法控制資源,但也不用承擔責任。
而服務上雲後,變成開發者有更高自主性,每個人都有責任,但自由沒有邊界,錯誤或責任反而無法追蹤。
因此當自由擴張後,需要很清楚的邊界,而各團隊可能將規範收攏在不同文件,要如何確保開發者都要套用這些邊界。
以往可能會交給 reviewer,但當基礎建設去中心化,就不能再靠人的記憶或默契來管理。
Police as code(PaC) 就是一個讓共識變成程式碼的方式,而程式碼可以被 git 管理,也就可以討論、追朔、Rollback,然後部署前需要先做 PaC 檢查,就能把責任從人交給流程。

並且依序探索、訪談需求、探索中找到第一批 Policy,並且讓大家能接受他。
例如救火時可能會被規則擋住,能透過註解的方式暫時繞過,規則可以破例但要被留下紀錄,除了有紀錄能回朔也有責任歸屬外,未來也能當作規則調整的評估。
其實想想不論導入什麼工具跟規範,似乎都能套用到類似上面的結構,算是思維上有收穫到的一場。
最重要的 takeway 是「治理不是限制,而是讓好規則被實踐」,而可協作、可版本化、可回滾的機制,才是真正能走長遠的治理。
更高效率低成本的 Observability 2.0 時代即將來臨
簡報:https://s.itho.me/ccms_slides/2025/6/17/6f7dda22-de5f-41e0-bd37-150f9482f818.pdf
這場誘因是 AWS 講者,談到隨著 AI 發展邊際效應很大,同時也需要更大的 Data 才能有底氣回答更多問題。
而真正讓 AI 變強,內部功能上有很多技術突破,也會有更多成本存在,因此 Observabilty 也帶來更大需求。
現況大型企業的挑戰:
- 必須監控的指標資料爆炸性成長
- 成本管理逐漸失控
- 微服務架構下系統複雜度跟依賴關係
- 企業規模大,要求變高,導致監控與延遲要求要越低
- API First 到 AI First 加劇 Observabilty 的問題
維護成本高、效能與延遲備受挑戰、成本不可控,工具互串的複雜度也變很高。
所以開始延伸出 Observability 2.0
- 1.0 傾向把 Logs、Metrics、Traces 分開,但 2.0 主張整合分析
- 以事件為中心,將單次的 request/operation 當成事件
- 不再是資源使用監控,而是以用戶體驗跟使用者行為的維度觀測
- 高維度資料,例如 user_id, session_id, feature_flag 等等
- 即時性的探索,不僅止於 Dashbroad,使用 GanAI 探索未知問題
- 地板價的儲存成本
高效率低成本 Lakehouse
以前處理 data 都是用關聯式資料庫,後來發展後資料暴增,如果要 query TB 等級的資料,沒有兩三天是沒辦法完成的。
後來 Date lake 出來但有門檻,因為不是找 query,必須要結合對 Data 有了解的人才能處理,而 Cloud data warehouse 關聯式資料庫、也可以很快處理 TB 等級資料,但缺點就是每一家的 query engine 不能選,也比較難 scale。
所以出現了 Data lake + Data warehouse -> lakehouse
- Data Lake + Warehouse 截長補短
- Datawarse : ACID, SQL
- Data Lake : Hive Table (無法做 Transaction 操作),儲存成本低
好處:
- 現在可以 ACID
- 有 Schema 變動可以快速達成
然後分享了一些正在導入 Lakehouse 的大廠的案例、使用場景分析、架構。
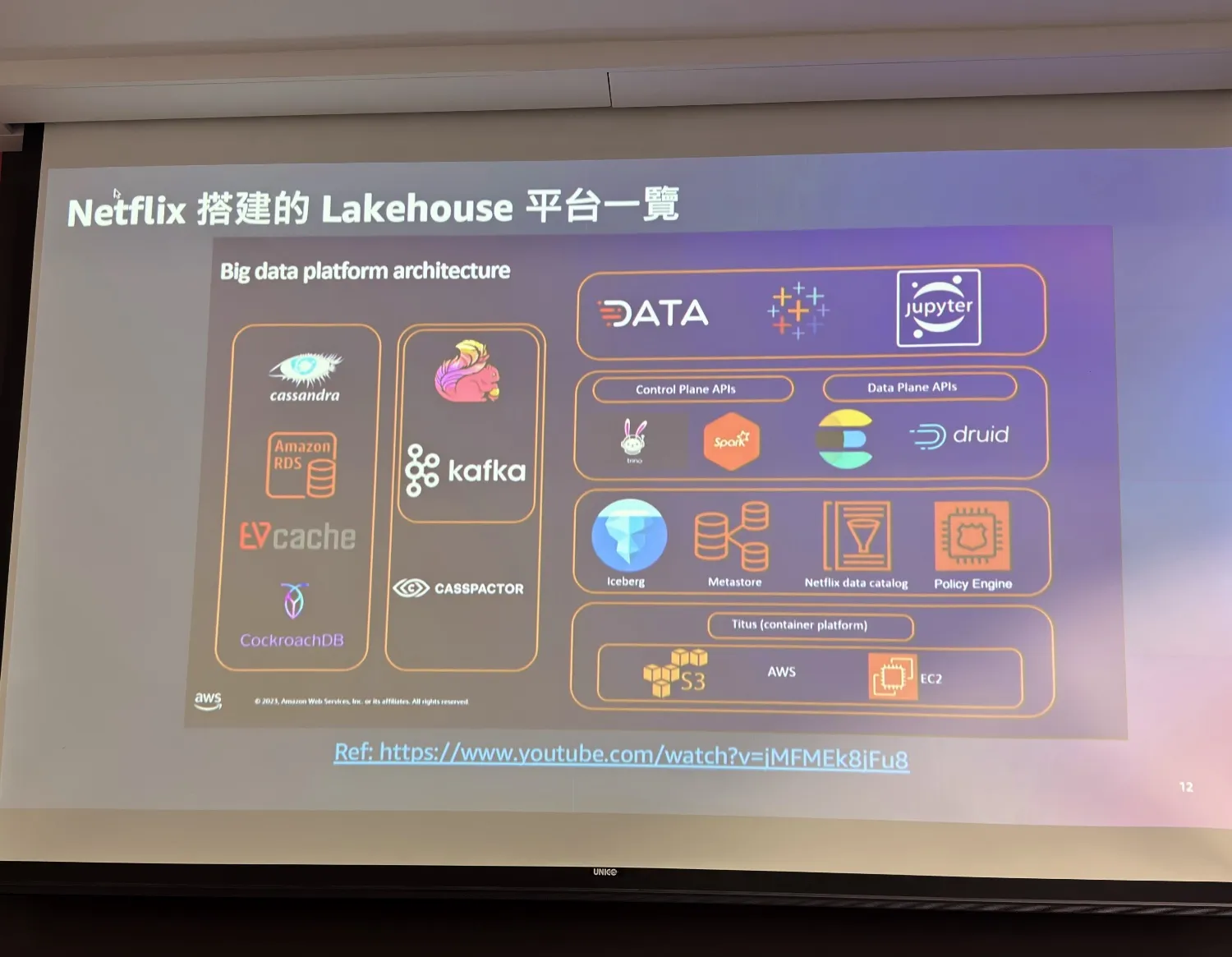
並在最後公布了 AWS 台北區域正式啟用。

結語
這篇卡了非常久,工作上有一些大調整,導致過了都快半年,我才有心力好好的來整理筆記。
回顧這兩天的議程,基本上沒學到什麼技術,但視野倒是被打開了不少。
平常在應用層開發,很容易把注意力放在功能、體驗、效能優化,但當站到 DevOps 和平台架構的角度上,思考的內容突然變成:
- 如何量化問題、定義問題
- 如何讓系統更容易被觀測、被理解
- 如何設計流程,讓組織可以持續演進而不是靠英雄式救火
比起單一技術,通常文化、流程與治理才是真正決定產品能不能長期維持品質、甚至存活的關鍵,這些都是我單純在開發時不曾仔細思考過的。
有時候這種不是來學會某種技術、工具的感受也不錯,期待未來有機會的話再來參加。
討論區
歡迎在下方分享你的想法,或是給我一個讚!